Last_value_in_period and first_value_in_period functions
The last_value_in_period and first_value_in_period functions augment the base last_value and first_value functions. Their purpose is to provide a solution for when the data engineer is unable to include zero value adjustment transactions as part of the ETL process.
These functions are the same syntax as last_value and first_value with the inclusion of an optional fourth parameter. This parameter defines the partition of the comparison partition. That is, return the last value if the value is from the last value in the period. If it is not, then null is returned rather than the actual balance.
These functions included additional window SQL calculations. Therefore, these may be less performant.
The basic syntax of the last_value function is:
last_value(operation(measure or attribute), query_groups(), {column to order by}, [Optional query_groups()]).
Without the optional fourth parameter, an example would be: last_value(sum(balance), query_groups(), {transaction date}).
With the optional fourth parameter, an example would be: last_value(sum(balance), query_groups()+{partner_id}, {transaction date},{partner_id}).
Parameters
You can separate the parameters in a first/last_value_in_period expression into operation, primary partition, "order by" column, and comparison partition.
- Operation
-
For example, (sum(balance)). This operation defines the aggregation type and the measure column.
- Primary partition query groups
-
This parameter defines which columns to partition the data by. Reference the following examples:
- query_groups()
-
Partitions by all grouping columns in the search. This is the default property for the majority of semi-additive measures.
- query_groups()+{partner_id}
-
Partitions by all grouping columns in the search and ensures that partner_id is always included.
- {partner_id}
-
Partitions by specific columns.
- query_groups()-{unit price, sales price}
-
Partitions by all grouping columns in the search with the exception of unit price and sales price.
- Order by column
-
For example, ({transaction date}). Specifies the sorting column to determine the "last" or "first" value, typically a date.
- Comparison partition query groups
-
Contains the columns for the date comparison partition.
- Not defined
-
The comparison partition is the order by column.
- {partner_id}
-
The comparison partition is the order by column and partner_id.
- query_groups(fiscalYear, fiscalMonth, fiscalWeek)
-
The comparison partition is the order by column and optionally the columns: fiscalYear, fiscalMonth, fiscalWeek. These extras are only included if they are included in the search.
- query_groups(fiscalYear, fiscalMonth, fiscalWeek)+{partner_id}
-
The comparison partition is the order by column and partner_id. In addition, include the optional columns.
Formula examples
Simple last date in period
For a simple last_date_in_period function, keep in mind that the requirement is that the result should return the maximum date in the period, defined by a date column. Define the period with a ThoughtSpot keyword such as yearly, monthly, or weekly. The function must verify that the partition’s date is the last date in the period. This signature is the same as the existing last_value function, therefore only the function name must be updated.
last_value_in_period ( sum ( BALANCE ) , query_groups ( ), { SnapshotDate })Additional partition columns
Let’s say that snapshot files are received from partners at different dates. Therefore, the result should return the value from the maximum date per partner. The fourth parameter includes any mandatory columns that should be included in the comparison dates partition clause. In the majority of circumstances, these would match those defined in the second parameter. Refer to the repeated use of {partnerid}.
last_value_in_period ( sum ( BALANCE ) , query_groups ( )+{partnerid}, { SnapshotDate },{partnerid})Date table attribute columns
Say that the data model includes a date dimensional table with columns that represent date periods, such as fiscal year, fiscal month, fiscal week. You can leverage these columns instead of the standard ThoughtSpot date periods. The comparison logic should include these attribute columns when they are included in the search. Therefore, they are optional partition-by columns.
last_value_in_period ( sum ( BALANCE ) , query_groups ( ), { SnapshotDate },query_groups(Fiscal Year, Fiscal Month, Fiscal Week))Additional partition columns and date table attribute columns
Say that the snapshot files are received from partners at different dates. In addition, the data model includes a date dimensional table with columns that represent date periods, like fiscal year, fiscal month, and fiscal week. You want a function that returns the value from the maximum date per partner, while including the date period columns as optional partition columns.
last_value_in_period ( sum ( BALANCE ) , query_groups ( )+{partnerid}, { SnapshotDate },query_groups(Fiscal Year, Fiscal Month, Fiscal Week)+{partnerid})Extended examples
Opening balances
In this scenario new inventory items are created throughout the year. Their opening balance should only be included if it is the first day of the period.
For this example, we will use the following opening balance formula:
fxOpeningBalance = first_value_in_period(sum(balance), query_groups()+{product}, {date})For the month of March a new product, oranges, was introduced. This was on the 15th March. However, currently there are no transactions for oranges in January or February.
| Date | Product | Balance |
|---|---|---|
1st January |
Apples |
10 |
1st January |
Pears |
10 |
1st January |
Grapes |
0 |
2nd January |
Apples |
10 |
2nd January |
Pears |
5 |
2nd January |
Grapes |
5 |
… |
… |
… |
31st January |
Apples |
5 |
31st January |
Pears |
10 |
31st January |
Grapes |
15 |
1st February |
Apples |
10 |
1st February |
Pears |
5 |
1st February |
Grapes |
20 |
… |
… |
… |
28th February |
Apples |
20 |
28th February |
Pears |
5 |
28th February |
Grapes |
0 |
… |
… |
… |
15th March |
Apples |
20 |
15th March |
Pears |
5 |
15th March |
Grapes |
0 |
15th March |
Oranges |
10 |
Let’s say you want to use first_value_in_period to find the opening balance from the beginning of the period defined in your table. Searching for fxOpeningBalance will give you the result that the opening balance is 20, defining the beginning of the period as January 1st. If you search for fxOpeningBalance by product, it will result in the following table:
| Product | Balance |
|---|---|
Apples |
10 |
Pears |
10 |
Grapes |
0 |
Oranges |
0 |
The first date in the table is January 1st. First_value_in_period verifies that the first transaction for Oranges in not the 1st of January. Therefore, null is returned.
Late arriving data files with null assumed as zero
In this scenario, data files are not always received on the same date. The business requirement is to return the inventory balance for the last file received by the partner. In addition, if a product is not received in a subsequent file, it is assumed to be zero.
In the following example, Acme Industries included monitors with a balance of 5 in the snapshot file for March 14th. They provided a new file on March 15th, which did not include a line item for monitors. Therefore, the balance for monitors was assumed to be zero on March 15th. Vandaly Industrial included all the products in both files, and had a zero balance for monitors on March 15th.
| Date | Partner | Product | Balance |
|---|---|---|---|
14th March |
Acme Industries |
Printers |
10 |
14th March |
Acme Industries |
Monitors |
5 |
15th March |
Acme Industries |
Printers |
5 |
13th March |
Vandaly Industrial |
Printers |
10 |
13th March |
Vandaly Industrial |
Monitors |
10 |
14th March |
Vandaly Industrial |
Printers |
5 |
14th March |
Vandaly Industrial |
Monitors |
0 |
For this example, we will use the following closing balance formula:
fxClosingBalance = last_value_in_period(sum(balance), query_groups()+{Partner}, {date},{partner})The last date in the table is March 15th. However, the last value for Vandaly Industrial is March 14th. Searching for fxClosingBalance returns the last available date by partner, which is the 15th for Acme Industries and the 14th for Vandaly Industrial.
Searching for fxClosingBalance by product produces the following table, with a total of 10:
| Product | Balance |
|---|---|
Monitors |
0 |
Printers |
10 |
The balance of Monitors is expected to be zero on the 15th March. This is because the balance for Monitors from Acme Industries was provided on the 14th. The last balance value for the partition combination of Acme Industries and Monitor is the 15th, therefore zero should be assumed for Monitors on the 15th. Note that the last_value function would return the balance of 5 for Monitors.
Closing balances not supplied
In this use case, the team receives account balances every day. Closed accounts do not currently have a follow-up transaction which zeroes the account out. If the last snapshot date received for the account is not the last day of data then the balance is considered to be zero.
In the following example the account, Darren, had a final snapshot balance received on March 14th. On the 15th of March, this is considered to be a value of zero.
| Date | Account | Balance |
|---|---|---|
14th March |
Darren |
10 |
14th March |
Marie |
10 |
15th March |
Marie |
5 |
For this example, we will use the following formula:
fxClosingBalance = last_value_in_period(sum(balance), query_groups(), {date})Searching for fxClosingBalance returns a result of 5. The last date in the table is March 15th. Only balances for this date are included in the result. Therefore, the account for Darren is not included in the total.
Searching for fxClosingBalance by account yields the following table:
| Account | Balance |
|---|---|
Darren |
0 |
Marie |
5 |
The balance of 10 for Darren is expected to be zero as this balance is from March 14th.
Employee headcount with Type II slowly changing attribute dimension
In the following example, the files are received every day. These files are at the employee level and indicate if the employee is a full-time employee.
At the start of the year, Sales and Marketing were separate departments. At the end of the year, there was a single department, Sales and Marketing. Field Tech is a department that exists at the end of the year but was not valid at the start. Human Resources existed at the start of the year but not at the end of the year.
| date | employee_id | full_time | department |
|---|---|---|---|
1st Jan |
EMP1001 |
1 |
Sales |
1st Jan |
EMP1002 |
1 |
Marketing |
1st Jan |
EMP1003 |
0 |
Engineering |
1st Jan |
EMP1004 |
1 |
Human Resources |
… |
… |
… |
… |
31st Dec |
EMP1001 |
1 |
Sales and Marketing |
31st Dec |
EMP1005 |
1 |
Engineering |
31st Dec |
EMP1002 |
1 |
Sales and Marketing |
31st Dec |
EMP1010 |
1 |
Field Tech |
For this example, we will use the following formula:
fxFTE = last_value_in_period(sum(FTE), query_groups(), {date})Using the formula above, you can calculate the yearly headcount by department. The last date in the year is December. Therefore, only full-time employee values from this month should be included. Note that during the year, the departments, Sales, Marketing, and Human Resources were valid, however they have no valid records for December.
Searching for fxFTE monthly department results in the following table:
| January | … | December | |
|---|---|---|---|
Engineering |
0 |
1 |
|
Field Tech. |
1 |
||
Human Resources |
1 |
||
Marketing |
1 |
||
Sales |
1 |
||
Sales and Marketing |
2 |
||
3 |
4 |
If you search for fxFTE yearly department, the following table results:
| Yearly | |
|---|---|
Engineering |
1 |
Field Tech |
1 |
Human Resources |
0 |
Marketing |
0 |
Sales |
0 |
Sales and Marketing |
2 |
4 |
For each year, the formula calculates the FTE and breaks it down by department. The last date in the year is December. Therefore, only FTE values from this month are included. Note that during the year, the departments, Sales, Marketing and Human Resources were valid, however, they have no valid records for December.
Available data date versus strict calendar date
These functions return the last value as determined by the resulting partition or ordering column. With data modeling, it is possible to return the value based upon the partition of available transactions (date from transaction table) or based upon a strict calendar interpretation (date from calendar table).
The example ER Diagram includes a DATE_DIM table. The join from INVENTORY_SNAPSHOT is a RIGHT OUTER JOIN. This ensures that we get all dates from the DATE_DIM table, even when there are no corresponding snapshots. This is critical for scenarios where a strict calendar date should be implemented for semi-additive measures.
Available Data Date
- Logic
-
If no transaction exists on the first day, use the last/first available date’s balance in the period (in this case, month).
- Implication
-
This approach assumes that balances persist and that the first recorded balance in the month is a valid proxy for the opening balance.
- Use Case
-
Common in inventory management, banking, and operational dashboards, where the first known balance in a period is considered the starting point.
Inventory Balance = last_value(sum(balance), query_groups(), {snapshot_date})Strict Calendar Date
- Logic
-
If there are no transactions on the last/first day of the period (in this case, month), then the balance is considered to be 0.
- Implication
-
This approach is useful for businesses that define an opening balance as the value at the exact start of the period (for example, 1st Jan at 00:00:00). If no data exists for that timestamp, then no balance is recorded.
- Use Case
-
This is often used in financial accounting where an explicit balance is required at the start of a period, and missing data means no value exists.
Inventory Balance = last_value(sum(balance), query_groups(), {date_id})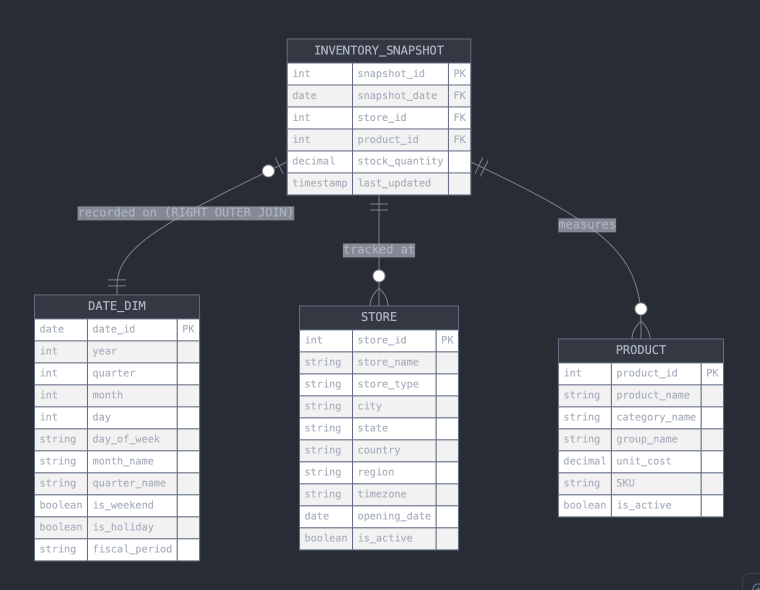
Limitations
-
Semi-additive functions cannot span multiple fact tables.
-
Semi-additive functions cannot contain only constant expressions. For example, if you create a formula with no references to a column, such as
last_value(sum(1), {}, {true}), ThoughtSpot will not support the function. -
You cannot combine different partitioning and ordering clauses in different semi-additive functions from the same table, in the same query. That is, a case where formula 1 partitions on Date and Product, and formula 2 partitions on Date, Product, and Client.
-
Average, Variance, Standard Deviation and Unique Count do not work with semi-additive functions across an attribution query. That is, multiple fact tables with at least one non-shared attribute.
-
* Semi-additive formulas when combined with unique count formulas may result the following query generation error.
Note that the unique count can be defined as the aggregate within the last_value function. That is,
last_value_in_period(unique count(store_id),query_groups(),{transaction_date}). -
Advanced aggregates (group, cumulative, moving and rank) cannot be used within the definition of semi-additive functions. Note they can be used to wrap these functions as outer aggregation.
-
ThoughtSpot will support
first_valueandlast_valuefunctions for Redshift and Google BigQuery beginning in the 10.1.0.cl release.
For more information, view the Introduction to Semi-additive Measures course on ThoughtSpot University.
Related information