Search data error reference
This reference identifies the error codes that can appear when you use Search data in ThoughtSpot, including the cause and suggested resolution.
Search data error codes
-
11028- Data samples are not supported for models with chasm traps.
-
11035- Unsupported query: unique count and a rank-related function coming from the same fact table.
-
11037- Formulas that mix aggregates and non-aggregate expressions are not supported.
-
11040- Rank-related function spanning multiple fact tables not supported
-
11046- No values are assigned to some or all Formula Variables
10102
- Description
-
Custom calendars store months as strings. As a month relates to a date, there is a natural numerical sorting order. This numerical order is based upon the configuration of the custom calendar. That is, the month of January is the first month in a Gregorian calendar. Assuming that the fiscal year starts in July, then January would be the 7th month. In the scenario where a user enters a search such as the following, Order Date >= May 2025, ThoughtSpot will need to generate the underlying SQL based upon the numerical month number of May. This would be a value of 11.
- Resolution
-
This error is displayed when this month number index is not defined. To resolve this error, the custom calendar must be updated via the ThoughtSpot custom calendar utility in the Data Management application.
To update the custom calendar, navigate to the calendar list in Data utilities, and select the more option menu
 . Select Update.
. Select Update.
Next, select the method of replacing a custom calendar as Existing table and select the table used for the calendar.
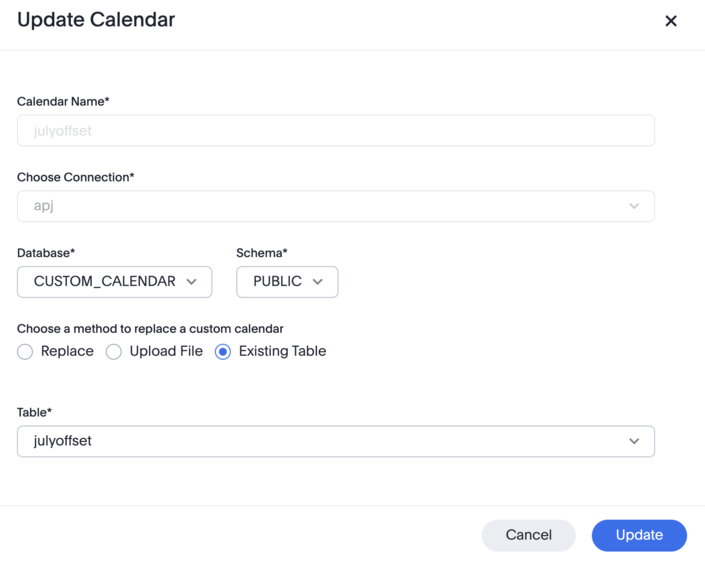
As part of this update, the month number index is set. Note that if the underlying database table is updated without also updating the ThoughtSpot custom calendar, then this sequence may be incorrect. Any updates to the underlying table must also involve a manual update to the custom calendar via the ThoughtSpot UI.
11026
- Description
-
Nesting group-aggregate formulas is not supported.
- Details
-
This error is displayed as a query generation error when a query plan detects that the underlying formula is defined with nested group functions. An example of nested group function is the following where:
-
the inner group aggregate is a level of detail calculation for sales at the country level.
-
the outer group aggregate creates a moving sum of the country sales that ignores any date filters. This ensures the moving calculation is correct when date filters are applied.
Sales by Country ( model formula) = sum(amount), {country}, query_filters())3 Month Average of Sales by Country= group_aggregate(moving_average(group_aggregate(Sales by Country,2,0,date),query_groups(), query_filters()-{date}) -
- Cause
-
ThoughtSpot does not support nested group functions. Refer to the formula reference for list of all group functions.
- Resolution
-
A data modelling solution is required to calculate the inner group function. In this example this could be one of the following constructs to pre-calculate the sales by country value:
-
a table or column in the underlying database;
-
a ThoughtSpot Search based View;
-
a ThoughtSpot SQL based View.
-
11027
- Description
-
Query must include at least one base table column.
- Details
-
This error is displayed when the search data query has not selected a token that references a column from the underlying database.
- Cause
-
With formulas, it is possible to create ThoughtSpot columns that do not reference the underlying database. The following is a simple example formula. If a search is defined with this single token, then the error will be displayed.
Current Date = today()A second example could involve a parameter, where the user has created a formula to calculate the number of days between the date specified by the parameter and the current date. As this formula does not reference a column in the database, this would return an error if this formula was the only token in the search.
Days Difference = diff_days(parameterDate, today()) - Resolution
-
Update the search to include a column that references the underlying database.
11028
- Description
-
Data samples are not supported for Models with chasm traps. Use Search to get sample data.
- Details
-
When a user selects the Data Samples tab from a Model, ThoughtSpot attempts to display 50 rows of data. If a chasm trap query plan is detected, then a warning message is displayed to the user.
- Cause
-
Schemas that may have multiple fact tables are joined through shared dimensional tables. This is known as a chasm trap. ThoughtSpot supports chasm traps for analysis. However, these are not supported for Model data samples. Refer to the Chasm trap article for further details.
- Resolution
-
Leverage Search Data to review columns and their values.
11029
- Description
-
The table data could not be retrieved. Table data is not supported for Models with aggregate column filters.
- Details
-
Models support the ability to define filters based upon aggregate formulas. This article provides an example for how aggregate filters can be used to protect PII information.
- Cause
-
Model data samples do not support the complex query planning required to return results with aggregate filters.
- Resolution
-
Leverage Search Data to review columns and their values.
11032
- Description
-
ThoughtSpot does not currently support complex usages of median, rank, rank_percentile, percentile, and aggregate SQL passthrough functions.
- Details
-
This error is displayed as a query generation error when the usage of median, rank, rank_percentile, and aggregate SQL passthrough functions are used in conjunction with an underlying query plan of a fan or chasm trap. Refer to this community article for further details regarding these complex query patterns.
The following is a simple example of a fan trap. Assume the data model has a central fact table for Sales. This is joined as a many-to-one to a region dimension table and another many-to-one join on the customer table.
[Sales] by [Region] [Count Customers]
The [Count Customers] token results in a fan trap. This ensures that there is no overcounting of the results.
- Cause
-
These functions do not currently support advanced formula planning. This is required to ensure that the results that are returned are correct.
- Resolution
-
For certain situations it may be possible to leverage the group_aggregate function to force an independent query plan for these functions. The fan trap example is extended to include a function to return the median value. This requires a formula to be defined:
fxMedian = median(sales)
The resulting search token is the following, which results in an error:
[Sales] by [Region] [Count Customers] [fxMedian]
The formula can be updated with the group_aggregate definition. Note that after the query_groups() section there is an additional definition of ‘+{}’. This is required so that query generation does not attempt to simplify the query plan.
fxMedian = group_aggregate(median(sales),query_groups()+{},query_filters())
11035
- Description
-
Unsupported query: unique count and a rank-related function coming from the same fact table.
- Details
-
last_valueis a ThoughtSpot formula function introduced in 9.12.0.cl . This function is designed to provide analysts the capabilities to create formulas for semi-additive measures. An example could be inventory balances.For example: "How much stock does Acme Corp maintain for each Region?"
A secondary metric could be Average Stock on Hand. A common definition for this is: balance of stock divided by the unique count of locations.
In ThoughtSpot this formula could be defined as:
last_value(sum(balance),query_groups(),{transaction date}) / unique count(location id)An alternative example could be a user asking the question as separate measures. For example: "Show me the balance and unique count of locations for each region".
In this scenario the search would return two measure columns: Balance & Unique Count Locations.
- Cause
-
In the example defined, the last value aggregate column is ‘balance’ and the unique count column is ‘location id’. Error 11035 is returned when the unique count column, ‘location id’, is derived from either the same fact table as balance or as a dimensional table that is joined to the fact table.
- Resolution
-
Unique count can be combined with last_value across a chasm trap query. Therefor, pending resolution for this limitation, an analyst can leverage group_aggregate to force a chasm trap query.
For example: The group_aggregate definition ensures a chasm trap is generated and the inclusion of query_groups()+{} ensures that this query plan is not optimized.
group_aggregate(unique count(location id), query_groups()+{}, query_filters())The complete formula would be:
last_value(sum(balance),query_groups(),{transaction date}) / group_aggregate(unique count(location id), query_groups()+{}, query_filters()). ---
11036
- Description
-
Unsupported query: nested aggregate function, for example, fx = max(avg(c1)).
- Details
-
This error is displayed in the formula editor when an aggregate formula is defined directly within another aggregate formula, for example,
average(sum(sales)). Note that this error may be displayed when an aggregate is wrapped around a column, such asaverage(total sales). In this scenario, the Model column would be defined with an aggregate formula, such astotal sales = sum(sales). - Cause
-
can’t use an aggregate function within an aggregate function.
- Resolution
-
To resolve this, group functions should be used to force the query generation to create a CTE query plan. That is, assume the business requirement is to return the average daily sales for each product. the formula would be defined as the following:
average daily sales = average(group_aggregate(sum(sales),query_groups()+{date(transactionDate)}, query_filters()))Where the following logic is applied
group_aggregate(sum(sales),query_groups()+{date(transactionDate)}, query_filters()) → calculate the daily sum of sales.average() → calculate the average of the daily sales for the level of detail of the search.The resulting query would be:
[Product] [Average Daily Sales].
11037
- Description
-
Formulas that mix aggregates and non-aggregate expressions are not supported.
- Details
-
This error is displayed in the formula editor when a formula incorrectly includes a combination of an aggregate expression and a non-aggregate expression (non-group-by).
The following is an example of a formula that results in an error. Where
-
region='apac' is the non-aggregate
-
sum(sales) is an aggregate
-
fx = if(region='apac' then sum(sales) else 0.
- Cause
-
Historically these formulas could be written in ThoughtSpot. However, these often resulted in SQL generation queries. In the example above, if the region column is not included in the search, then a group by sql query would be returned. This is because the:
-
aggregate function is calculated across all rows of data : sum(sales).
-
non-aggregate is a calculation at the row level : region='apac'.
-
- Resolution
-
The formula must be re-written with the following as examples:
Option 1: wrap the non-aggregate column in an aggregate function.
fx = if(max(region)='apac' then sum(sales) else 0Option 2: re-write the function as an aggregate if formula.
fx = sum_if(region='apac', sales)
11038
- Description
-
Range of data queried exceeds the configured time limit for a date column. This occurs when attempting to query data spanning more than the maximum allowed time range defined in the Model constraints.
- Details
-
This error appears when a search query attempts to access data spanning a date range that exceeds the constraints defined in the ThoughtSpot Model’s TML configuration. In the following example, the error occurs when trying to query order date data spanning more than 5 years.
For example, if a user attempts to search without any date filter:
[Sales] by [Product] [Region]
The system would apply the error if the underlying data spans more than 5 years for the order date column.
- Cause
-
ThoughtSpot Models can be configured with mandatory date range constraints to enforce query performance best practices. These constraints are applied before queries are dispatched to the underlying data warehouse, preventing overly broad date ranges that could result in performance issues, timeouts, or excessive resource consumption.
The constraints are defined in the Model’s TML file using the date_range_condition configuration, which specifies:
-
The table containing the date column
-
The specific date column to constrain
-
The maximum duration allowed (for example, 5 years)
-
The time bucket (YEAR, MONTH, etc.)
When a search query would result in accessing data beyond the configured time range constraint, error 11038 is generated.
Refer to the documentation page for TML definition.
-
- Resolution
-
- For Spotter/Search data
-
Add an explicit date filter to limit the date range within the allowed constraints:
For example:
[Sales] by [Product] [Region] last 3 years
- For the data model
-
This error may also be displayed when applying a Model filter. In order to apply a filter to a Model with a constraint, the following options are available:
-
Remove the constraint, apply Model filter, and then re-apply constraint.
-
Add a temporary date filter to the Model, apply Model filter, and then remove temporary date filter.
-
11040
- Description
-
Rank-related function spanning multiple fact tables is not supported.
- Details
-
Assume the Model definition has the underlying data tables. This is a chasm trap Model where there are two fact tables: Inventory and Purchases. There is a single shared dimension: date. Store and Supplier details are not shared. Store is joined to Inventory and Supplier to Purchases.
dimStore ← factInventory → dimDate
dimSupplier ← factPurchases → dimDate
- Cause
-
The following formula definition can be saved, however, it will generate the query generation error:
fxQueryGenError = last_value(sum(factInventory.balance), {dimSupplier.Code}, {dimDate.Date})The reason is that the join path between the columns factInventory.balance and dimSupplier.Code is via a chasm trap. This formula will return incorrect results.
- Resolution
-
This Model would need to be augmented so that there is a direct join between factInventory and dimSupplier.
11045
- Description
-
As of 10.12.0.cl, it is not possible to use a Set with a formula’s filter condition. The resulting SQL result is invalid. This is an interim error message that will be displayed until this feature is delivered.
- Details
-
A conditional formula can be written with either of the following syntax examples:
-
sum_if(region='west', sales)
-
group_aggregate(sum(sales),query_groups(),{region='west'})
-
group_aggregate(sum_if(region='west', sales),query_groups(),query_filters())
-
if (sum(sales) >0 ) then region else ‘not in region’
If the defined filter is a Set rather than a Model column then the error will be displayed. That is:
-
sum_if(regionSet='west', sales)
-
group_aggregate(sum(sales),query_groups(),{regionSet='west'})
-
group_aggregate(sum_if(regionSet='west', sales),query_groups(),query_filters())
-
if (sum(sales) >0 ) then regionSet else ‘not in region’
Note that the vs keyword will generate this error if the Set is used as the comparison column. This is because the VS keyword generates formulas as per the second example above.
That is:
[Sales] ([regionSet='west'] vs [regionSet='east'])will result in system formulas defined as:
-
group_aggregate(sum(sales),query_groups(),{regionSet='west'})
-
group_aggregate(sum(sales),query_groups(),{regionSet='east'})
-
- Cause
-
This is an intentional error as the resulting SQL results are not correct.
- Resolution
-
This feature is a backlog delivery item for the Set’s feature capabilities.
11046
- Description
-
An error is detected when a formula variable is defined in a row-level security (RLS) rule and the variable value is unassigned. The following is an example of an RLS rule. The logic is to compare the region column to the region formula variable. The logic validates that the region formula variable is defined and that a value is assigned.
region = ts_var(region) - Resolution
-
Ensure that all variables referenced in the RLS rules have an assigned value for the user in question.
11047
- Description
-
Formula variables support a special wildcard value:
WILDCARD_ALL. The result is that the user should have access to all values of the associated column. The associated row-level security (RLS) rule can only be defined with equals=andin.region = ts_var('region') - Resolution
-
Update the associated RLS rule to ensure that rules are defined with the operators equals (
=) orin. That is, operators!=andnot inare not supported.
22001
- Description
-
Multiple query paths detected. The selected path is the first table based upon alphabetical sorting of the table names.
- Details
-
- Simple example
-
The following image represents a chasm trap data model. Refer to this article for further details on chasm traps and attribution.
Scenario 1: A user has selected a column (or columns) from the group dim table and the datetime dim table. This results in two possible root tables and resulting paths to join these columns:
Option 1: Join through the membership fact table.
Option 2: Join through the group tag fact table.
These root tables are considered equal as both paths have the same number of children nodes. That is, both paths join to group dim and datetime dim. In this scenario, ThoughtSpot will select the path based upon the alphabetical sorting of the root tables. As G is sorted before M, the group tag fact table is selected.
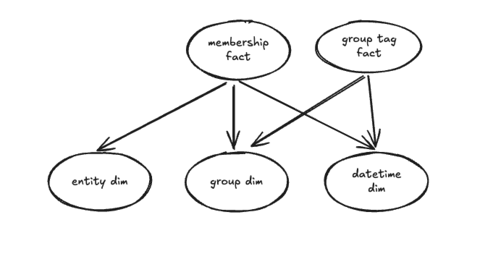
Scenario 2: A user has selected a column (or columns) from the group dim table, datetime dim table, and the entity dim table. In this scenario, the path via membership fact results in three children nodes: entity dim, group dim, and datetime dim. Whereas group tag fact has only two children: group dim and datetime dim. Therefore, the resulting query joins through the membership fact table.
- Extended example
-
The following image represents an extended chasm trap data model. Note that F indicates a fact table and D indicates a dimensional table. Joins are many-to-one from the fact tables to the dimensional tables.
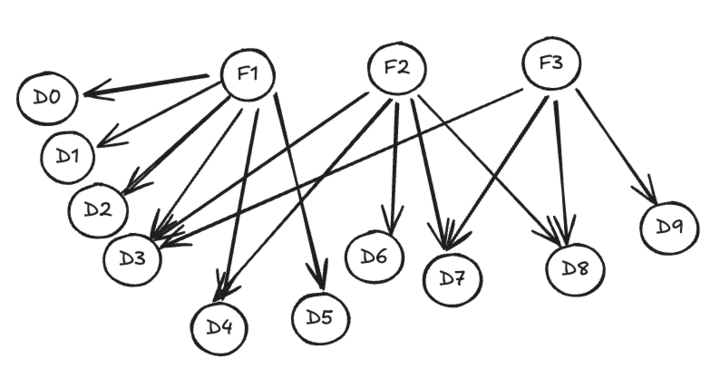
Scenario Query 1: D0 D1 D2 D3 D4 D5
This query will NOT display a warning message. F1 provides coverage for all selected columns.
Scenario Query 2: D0 D1 D2 D3 D4 D5 D6 D7 D8 D9
This query will NOT display a warning message where the following rules have been applied:
-
F1 is the first maximal root. That is, this fact table has the most related dimensional tables that meet the columns selected.
-
In this case, F1: D0 D1, D2, D3, D4, D5 (six children nodes).
-
Note that these columns are not removed from the context for future evaluation.
-
-
F2 and F3 have a tie as both have three related dimensional tables, when those columns from the first maximal root are removed. A tie breaker is required to determine which fact table to join D7 through. That is, this is available for both F2 and F3.
-
F2: D6, D7, D8 (three children nodes)
-
F3: D7, D8, D9 (three children nodes)
-
-
F2 and F3 have an equal number of related dimensional tables. Therefore, the original context is considered as the first tie breaker.
-
F2: D3, D4, D6, D7, D8 (five children nodes)
-
F3: D3, D7, D8, D9 (four children nodes)
-
F2 is considered as the second maximal root and F3 the third.
-
Therefore D7 is joined through F2 rather than F3.
-
Scenario Query 3: D0 D1 D2 D3 D5 D6 D7 D8 D9
This query will display a warning message where the following rules have been applied. Specifically, the warning is in relation to which table D7 and D8 are joined through.
-
F1 is the first maximal root. That is, this fact table has the most related dimensional tables that meet the columns selected.
-
In this case, F1: D0, D1, D2, D3, D5 (five children nodes)
-
Note that these columns are not removed from the context for future evaluation.
-
-
F2 and F3 have an equal number of related dimensional tables.
-
F2: D6, D7, D8 (three children nodes)
-
F3: D7, D8, D9 (three children nodes)
-
The original context does not break the tie between F2 and F3. This is because both are joined to D3 and neither are joined to D5.
-
Therefore, alphabetical sorting of the table name is required to break the tie. F2 is considered as the second root as this is sorted first. Therefore, D7 and D8 are joined through F2 rather than F3.
-
-
- Resolution
-
Consider the following options where the desired behaviour is to join via the membership fact:
- Option 1
-
Rename the tables so that membership fact sorts first. That is, add a prefix to membership fact such as a_membership_fact.
- Option 2
-
For TABLE queries, a column can be selected from the entity dim table. This can be marked as hidden. Hidden columns are included in the query plan. Note that for CHART queries, not visualised columns are not included in the query plan.